Forward

Contents
Contents
Until now
Lately, I have found myself spending a decent amount of time on open-source data projects. With that, I hope to keep this blog up to date on what I am working on.
Over the many years of my programming career, I have switched between a few different languages. I started with parallel and distributed computing in Java, then moved on to doing OpenBSD kernel programming in C. Later I did some web services with Python and then Javascript (node.js). When I got into machine learning I picked up Scala and Spark. Then when it was time to make money, I built out SaaS products in Ruby on Rails and more Javascript (React/Vue). Somewhere along in there, I also picked up Go when I was thrust into Data Science to do real-time machine learning predictions.
What will I be writing about?
The areas that have most interested me lately have been around data systems, distributed computing, and moving data between tools systems, and language boundaries.
There is a lot of development effort going into creating open-source software for data. With all of the software being created, many developers are choosing a language based on what they are trying to accomplish. You have the C and C++ crowd squeezing every ounce of performance for computation. Then you have the Python crowd, trying to work at a high level but ultimately falling back on C/C++ to do various data things. You have the Rust crowd wrangling performance by avoiding the garbage collector. You have the JVM crowd doing Java, Scala, Kotlin, etc… Don’t forget about the Spark crowd which includes the Python, JVM, and C++ crowds.
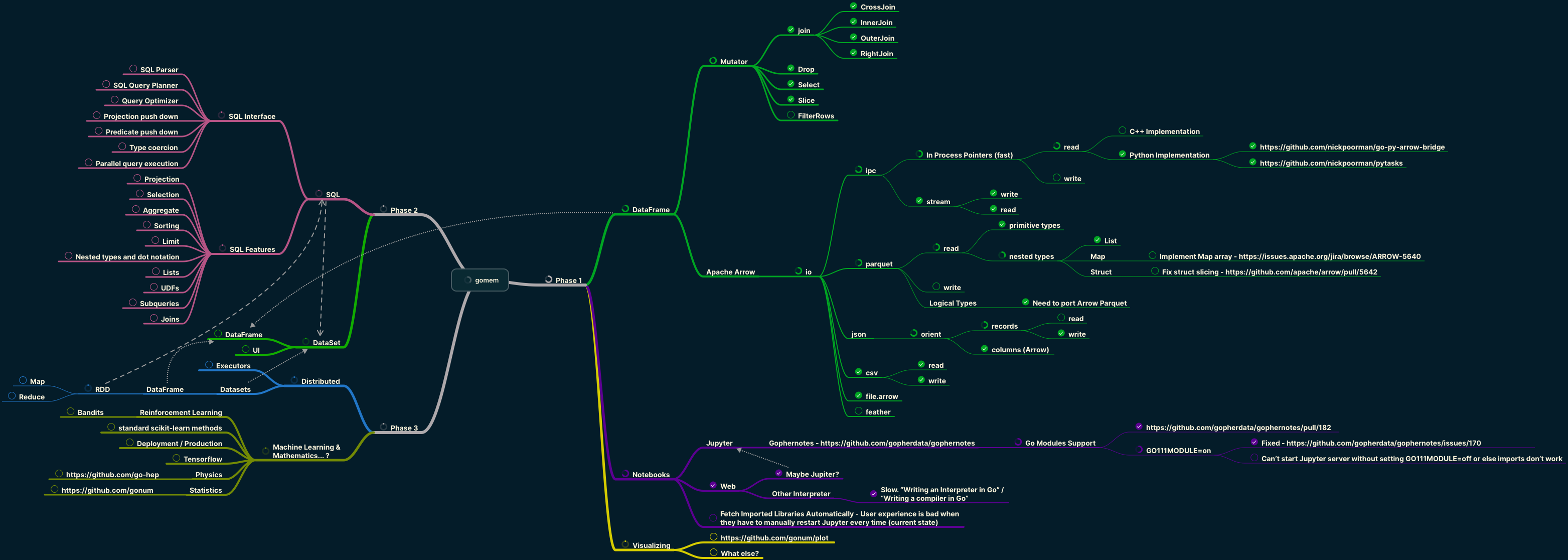
Concurrency and simplicity
Well if all of this wasn’t enough, my goal is to help build up the Go crowd. There are so many benefits to Go, from the speed of the compiler to the simplicity of the language and most importantly the ease of concurrency. A few months ago I started to build out a mental map of what the state of data software looks like in Go and what it would take to enable it for mainstream use. You can get a rough idea from the image at the top of this post on where my head is at. So stay tuned!